A Pedagogical Guide to GenAI Observability, GenAI Evaluation, and GenAI Monitoring

Unlock trustworthy AI: Master evaluation, monitoring, and observability. Discover why DevOps thinking fails AI and how a "helix" model elevates your systems. Stop firefighting; proactively improve your AI, catch issues early, and eliminate black boxes.
Unlock trustworthy AI: Master evaluation, monitoring, and observability. Discover why DevOps thinking fails AI and how a "helix" model elevates your systems. Stop firefighting; proactively improve your AI, catch issues early, and eliminate black boxes.
Building the Foundation for Trustworthy AI
This guide defines and explains what is necessary to establish the complete foundation for trustworthy AI: AI Evaluation, AI Monitoring & AI Observability.
Critical Questions Answered
Part I: Clearing the Mist - The Foundation
1.1 The Confusion Problem
A lot of confusion exists around the terms AI/ML monitoring, AI/ML observability, and AI/ML evaluation.
Common Misconceptions
- "Observability and monitoring are the same"
- "Observability in AI/ML is tracing."
- "Observability is just monitoring but with more metrics."
- "Evaluation is just monitoring but before deployment."
This leads to confusion, debates, scoping issues, a lot of energy lost, and sometimes even the abandonment of initiatives. Let's clarify these terms once and for all.
1.2 The Three Pillars - Simple Definitions
Detailed Definitions
1.3 The Paradigm Shift - Why These Three Pillars Matter
Traditional Software
- Deterministic Logic
- Input X → Output Y, always
- DevOps Loop (∞)
- Fix bugs and return to state
AI/ML Systems
- Probabilistic Behavior
- Input X → Likely output Y
- AI/ML Helix (🌀)
- Each iteration elevates system
From DevOps Loops to AI/ML Helixes
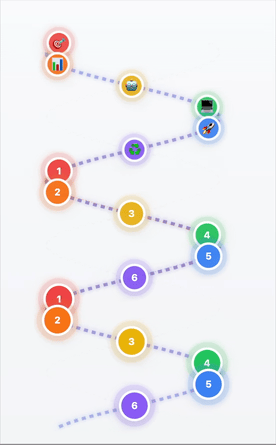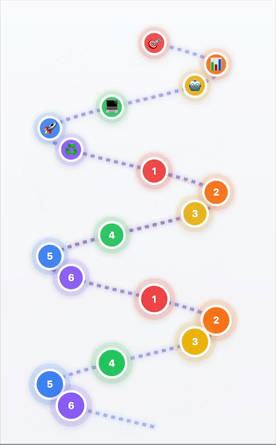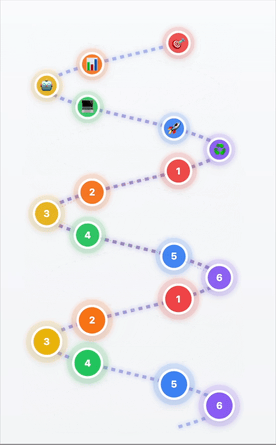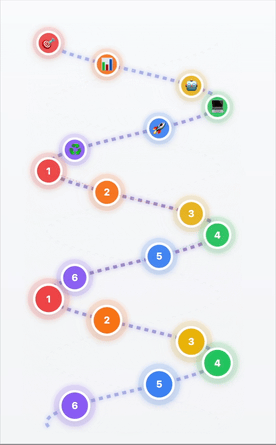
- 1Scoping & Problem Definition → What are we solving?
- 2Data Investigation & Preparation → Quality data = quality AI
- 3Model Selection & Adaptation → Right tool for the job
- 4Application Development → Building the solution
- 5Deployment & Scaling → Going live
- 6Continuous Improvement → Learning & ascending
A Concrete Example: The Ascending Spiral
Consider a chatbot that starts hallucinating:
- Monitoring alerts:
Accuracy dropped from 92% to 78%(Detection) - Observability traces:
Hallucinations correlate with documents chunked > 512 tokens(Root cause) - Evaluation measures:
New chunking strategy improves faithfulness from 0.7 to 0.9(Validation)
Key insight: You don't just "fix" the chunking bug. You've learned about optimal chunk sizes, improving your data prep, evaluation criteria, monitoring thresholds, and observability traces.
1.4 Observability: The Critical Distinction
Why your DevOps observability isn't enough for AI: AI systems have unique challenges (non-deterministic, data-dependent, etc.) that traditional monitoring can't capture.
| Aspect | Traditional IT Observability | AI / ML Observability |
|---|---|---|
| Logs | Application errors, requests, system events | Inference logs, prediction errors, model inputs/outputs |
| Traces | Tracking a request across multiple services (microservices, APIs) | Tracking data flow from collection → preprocessing → prediction (lineage) |
| Technical Metrics | Response time, availability, CPU/GPU usage | Inference latency, execution cost, GPU saturation |
| Business Metrics | API success rate, SLA compliance | Business-aligned KPIs (fraud detected, increased sales, medical errors avoided) |
| Data Quality | Barely covered, except basic validation | Checking feature distribution, missing values, data drift |
| Model Performance | Not applicable | Precision, recall, F1-score, AUC, model degradation detection |
| Bias & Fairness | Not relevant | Bias detection (gender, age, origin), fairness of predictions |
| Explainability | Not relevant | Techniques like SHAP, LIME to understand why the model predicts X |
| Alerts | System errors, downtime | Performance degradation, data anomalies, model drift |
| Final Objective | Ensure infrastructure/application reliability | Ensure reliability, transparency, and positive impact of AI models |
Part II: The Deep Dive - Understanding Each Pillar
While each pillar has distinct responsibilities, they're deeply interconnected. We'll explore each individually first, then highlight their connections through 🔗 Bridge Boxes that show how they work together.
2.1 AI/ML Evaluation - Setting the Bar
Think of AI/ML evaluation as the element that defines success for your models. It's about establishing clear, objective criteria for what "good" looks like in the context of your specific application.
Evaluation Layers
- 1Level 0: Foundation (Data) - Poor data = poor results regardless of architecture. Garbage in = Garbage out
- 2Level 1: Simple Metrics - Baseline understanding: task success rate, response accuracy, error frequency
- 3Level 2: Component Evaluation - RAG: Retrieval vs Generation | Agents: Tool selection vs Execution vs Planning
- 4Level 3: Multi-dimensional - Quality is multi-faceted: faithfulness, relevance, coherence, toxicity checks
- 5Level 4: Continuous Evaluation - Lab performance ≠ Production performance. Online evaluation with real users
Types of Evaluation
Timing: Offline vs Online
Method: Automated vs Human
Unlike traditional ML where you have clear labels (cat vs dog), GenAI evaluation is fundamentally different - often no single "correct" answer exists.
The Foundation Layer - Data Evaluation
The 80/20 Rule
Universal Data Quality Checks
Architecture-Specific Focus
| Problem Type | RAG Systems | Agent Systems | Fine-tuning |
|---|---|---|---|
| Format Issues | PDFs with tables poorly extracted | Tool output formats inconsistent | Training data in mixed formats |
| Missing Info | No metadata (author, date) | Tool descriptions lack params | Missing labels or features |
| Conflicting Data | Multiple doc versions contradict | Tools with overlapping purposes | Train/test contamination |
| Sensitive Data | PII in documents | API keys in tool configs | Personal data in training set |
Architecture-Specific Evaluation Deep Dive

RAG System Evaluation
Document Chunking Evaluation
| Strategy | Quality | Setup Time | Best For |
|---|---|---|---|
| 📏 Fixed Size | ⭐ | 5 min | Logs, simple uniform text |
| 🔄 Recursive | ⭐⭐⭐ | 30 min | Code, Markdown, structured content |
| 🧠 Semantic | ⭐⭐⭐⭐ | 2-3 hrs | Articles, blogs, narrative text |
| 🏗️ Structural | ⭐⭐⭐⭐⭐ | 1-2 days | Reports, PDFs, complex docs |
| 🤖 Agentic | ⭐⭐⭐⭐⭐ | 1 week+ | Strategic, mission-critical content |
Chunking Evaluation Metrics:
chunking_metrics = {
"avg_chunk_size": 450, # Target: 300-600 tokens
"chunk_size_variance": 0.15, # Target: <0.20 (consistency)
"semantic_coherence": 0.82, # Target: >0.75 (topic unity)
"boundary_quality": 0.88, # Target: >0.80 (clean splits)
"overlap_effectiveness": 0.78 # Target: >0.75 (context preservation)
}The RAG Triad Framework
RAG systems require evaluating three interconnected components:
| Component | Metric | Target | Why Critical |
|---|---|---|---|
| Retrieval | Context Precision | 0.85-1.0 | Poor retrieval → hallucinations |
| Retrieval | Context Recall | 0.80-1.0 | Missing context → incomplete answers |
| Generation | Faithfulness | 0.85-1.0 | Prevents making things up |
| End-to-end | Answer Correctness | 0.80-1.0 | Business value metric |
Vector Database Performance
Performance Targets:
- • Query latency: <100ms
- • Throughput: >100 QPS
- • Recall@k: >0.90
- • Memory: <4GB per 1M vectors
Algorithm Selection:
- • HNSW: Best all-rounder (start here)
- • Faiss IVF: Very large scale
- • ScaNN: High performance needs
- • ANNOY: Static data only
Agent System Evaluation
Not all agents are created equal. The evaluation approach must match the agent's autonomy level:
Agents require a dual-layer approach: Component-Level (debugging) and End-to-End (user experience).
| Aspect | Metric | Success Criteria | Technique |
|---|---|---|---|
| Tool Selection | Tool Correctness | >0.90 | Deterministic matching |
| Tool Parameters | Parameter Accuracy | >0.95 | Schema validation |
| Tool Efficiency | Redundant Usage | <10% overhead | Path analysis |
| Planning Quality | Plan Coherence | >0.85 | LLM-as-Judge |
| Task Completion | Success Rate | >0.85 | Binary + partial credit |
| Error Recovery | Recovery Success | >0.75 | Fault injection testing |
Key Metrics
Safety Checks
Component Tracing and Observability
For complex agents, you need to trace execution at a granular level:
End-to-End Tracing
Follow request through all components
Component Isolation
Identify bottlenecks
State Monitoring
Track internal state evolution
Agent Evaluation Frameworks
| Framework | Primary Focus | When to Use |
|---|---|---|
| DeepEval | Comprehensive Testing | Development & CI/CD |
| AgentBench | Multi-Environment Benchmarking | Comparative evaluation |
| Phoenix (Arize) | Observability & Tracing | Production debugging |
| LangSmith | Full Lifecycle | Enterprise workflows |
Evaluation Integration Patterns
Best Practices for Integration:
- Continuous Integration: Run automated tests on every commit
- A/B Testing: Compare agent versions with real traffic
- Human-in-the-Loop: Sample 5-10% for human review
- Regression Testing: Ensure changes don't break existing capabilities
Safety Evaluation Dimensions:
- Boundary Respect: Agent stays within authorized scope
- Safety Protocol: Follows safety guidelines
- Action Authorization: Only performs allowed operations
- Resource Limits: Respects computational budgets
🔗 Real-World Example: Debugging a Customer Service Agent
Problem: Agent fails 30% of order lookup tasks
Component-Level Evaluation Results:
- Tool selection: 95% correct ✅
- Parameter extraction: 65% correct ❌ ← Root cause found
- Tool execution: 90% correct ✅
- Task completion: 70% success 📉
Observability Trace Reveals:
- Agent struggles with order IDs containing special characters
- Parameter validation logic too strict
- No retry logic for malformed parameters
Solution Implemented:
- Add parameter normalization (remove special chars)
- Relax validation for common edge cases
- Implement retry with parameter correction
Results After Fix:
- Parameter extraction: 65% → 92% ✅
- Task completion: 70% → 88% 🎉
- User satisfaction: +25% improvement 📈
Unlike RAG systems where you primarily evaluate retrieval + generation, agents require evaluating:
- Decision-making (tool selection, planning)
- Execution (parameter handling, API calls)
- Adaptation (error recovery, plan adjustment)
- Safety (boundary respect, authorization)
- Efficiency (path optimization, resource usage)
This complexity demands a layered evaluation strategy combining deterministic metrics, LLM-as-Judge assessments, and comprehensive observability.
Fine-tuned Model Evaluation
Fine-tuning is the right choice when you need deep domain expertise, consistent tone/style, or reduced latency that can't be achieved through prompting alone. However, it's computationally expensive and requires significant expertise.
Decision Matrix: Should You Fine-tune?
| Criterion | Threshold | Rationale |
|---|---|---|
| Query Volume | > 100,000/month | High volume justifies training costs |
| Domain Specificity | < 30% vocab overlap | General models lack domain knowledge |
| Tone Consistency | > 90% required | Brand voice critical |
| Latency Requirements | < 500ms | Need edge deployment |
| Data Availability | > 10,000 quality examples | Sufficient for effective training |
4+ criteria met: Strongly recommend | 2-3 met: Consider carefully | 0-1 met: Use RAG or prompting
Catastrophic Forgetting - The Silent Killer
Critical Evaluation Dimensions
Domain Expertise Gain
Style & General Capability
Catastrophic Forgetting Assessment:
catastrophic_forgetting_score = {
"general_qa_retention": 0.92, # Baseline: 1.0, Target: >0.90
"math_capability": 0.85, # Baseline: 1.0, Target: >0.85
"reasoning_retention": 0.88, # Baseline: 1.0, Target: >0.85
"language_understanding": 0.94, # Baseline: 1.0, Target: >0.90
"overall_forgetting_rate": 0.08 # Target: <0.10 (10%)
}
# Red Flags:
# - ANY task drops >10% from baseline
# - Average degradation >5%
# - Critical capabilities completely lostMitigation: Mixed Training (10-20% general data), Replay Buffer, Regularization (LoRA, PEFT)
Domain Expertise Assessment:
domain_expertise_metrics = {
# Core domain performance
"domain_task_accuracy": 0.89, # vs baseline: 0.72 ✅ (+17%)
"terminology_precision": 0.93, # Correct term usage
"edge_case_performance": 0.78, # vs baseline: 0.55 ✅ (+23%)
# Depth indicators
"concept_explanation_quality": 0.87, # LLM-as-Judge
"technical_detail_accuracy": 0.91, # Expert validation
"clinical_note_quality": 0.85 # Human expert rating
}
# Success Criteria:
# - Domain accuracy improvement >20% (minimum)
# - Terminology usage >90% precision
# - Edge cases improve >25%Fine-tuning ROI Calculation:
fine_tuning_roi = {
# Costs
"training_compute": "$5,000",
"data_preparation": "$15,000",
"evaluation_testing": "$8,000",
"ongoing_maintenance": "$3,000/month",
# Benefits
"performance_gain": "+22% domain accuracy",
"latency_reduction": "-45% (2.1s → 1.2s)",
"cost_per_query": "-60% ($0.15 → $0.06)",
"quality_improvement": "+18% user satisfaction",
# ROI calculation
"break_even_point": "250,000 queries",
"monthly_savings": "$9,000",
"payback_period": "5 months"
}Fine-tuned vs Baseline Comparison
| Dimension | Baseline | Fine-tuned | Assessment |
|---|---|---|---|
| Domain Accuracy | 72% | 89% | ✅ +17% improvement |
| General Tasks | 92% | 85% | ✅ -7% acceptable |
| Latency (p95) | 2.1s | 1.2s | ✅ -43% improvement |
| Cost/1K queries | $0.15 | $0.05 | ✅ -67% savings |
| Style Consistency | 78% | 94% | ✅ +16% improvement |
Connecting Evaluation to Other Pillars
Now that we've covered the core concepts, foundation, and architecture-specific evaluations, let's understand how evaluation connects to the other two pillars.
🔗 Bridge Box: Fine-tuning → Monitoring
What to Monitor Post-Fine-tuning:
- Domain drift: Are medical terms evolving?
- Catastrophic forgetting in production: Is general capability declining?
- Style drift: Is brand voice consistent over time?
- Retraining triggers: When performance drops below threshold
Example: Medical model degradation detected after 6 months (new drug terminology). Observability traces issue to missing terms → Evaluation validates retraining need → Updated model deployed.
🔗 Bridge Box: Foundation Evaluation → System Evaluation
Why Foundation Layer evaluation matters:
- Data quality issues → Cascade to all downstream metrics
- Poor chunking → Degraded retrieval precision regardless of embedding model
- Suboptimal vector DB → Latency issues that no prompt engineering can fix
Example: A team spent 2 months optimizing their RAG prompts, achieving only marginal gains. One week of chunking evaluation and optimization improved their answer quality by 35%. The foundation matters!
🔗 Bridge Box: Evaluation → Monitoring
What Evaluation provides to Monitoring:
- Baselines: Your evaluation metrics become monitoring thresholds
- Alert criteria: When metrics drop below evaluation standards
- Expected ranges: Normal vs anomalous behavior definitions
Example: If evaluation shows 85% accuracy is your baseline, monitoring alerts when production drops below 80%
🔗 Bridge Box: Evaluation ↔ Observability
The Two-Way Street:
- Evaluation → Observability: Metrics help identify which components need investigation
- Observability → Evaluation: Root cause insights improve evaluation criteria
Example: Observability reveals hallucinations occur with chunks >512 tokens → Evaluation adds "chunk size distribution" metric → Better system overall
2.2 AI/ML Monitoring - Keeping Watch
📍 Important
Monitoring is fundamentally about watching deviations from your baseline. Think of it as a continuous comparison between expected behavior (baseline from evaluation) and actual behavior (what's happening in production).
Universal Monitoring Dimensions
| Dimension | What It Tracks | Why Critical | Universal Metrics |
|---|---|---|---|
| Performance | System speed and reliability | User experience, cost control | Latency (P50, P95, P99), throughput, error rate |
| Quality | AI output accuracy | Core business value | Task success rate, quality scores, user satisfaction |
| Stability | Consistency over time | Prevents silent degradation | Drift scores, variance metrics, anomaly rates |
| Resources | Computational costs | Budget and scalability | Token usage, API costs, GPU utilization |
The Three Drifts
Detection: Statistical tests (KL divergence, PSI), performance trends, metrics vs baseline
Alert Severity Framework
- 🟢 Info: Within rangeLog only
- ⚠️ Warning: 10-20% deviationInvestigate (4hrs)
- 🔴 Critical: >20% deviationUrgent (30min)
- 🚨 Emergency: Service downPage On-Call
System Health Monitoring (Universal)
| Metric | Good Range | Warning | Critical | Why Monitor |
|---|---|---|---|---|
| API Availability | 99.9%+ | <99.5% | <99% | Service reliability |
| Latency P50 | <1s | >1.5s | >2s | User experience |
| Latency P95 | <2s | >3s | >4s | Worst-case performance |
| Error Rate | <1% | >2% | >5% | System stability |
| Token Usage | Budget compliant | 80% budget | 90% budget | Cost control |
Architecture-Specific Monitoring
🔍 RAG Monitoring Checkpoints
Query & Retrieval
- Query length distribution (±30% baseline)
- Out-of-domain rate (<5%)
- Context precision/recall (0.85+)
- Retrieval latency (<500ms)
- Zero results rate (<5%)
Generation & User
- Faithfulness (0.85+)
- Answer relevance (0.85+)
- User satisfaction (>4.0/5)
- Follow-up rate (<15%)
- Cost per query (budget)
🤖 Agent Monitoring
Task & Tool Metrics
- Task success rate (>0.85)
- Tool selection accuracy (>0.90)
- Parameter correctness (>0.95)
- Redundant tool calls (<10%)
Safety & Planning
- Authorization violations (0)
- Boundary breaches (<1%)
- Plan efficiency (<20% overhead)
- Loop detection (0)
🎯 Fine-tuned Model Monitoring
Domain Performance
- Domain accuracy (baseline -5%)
- Terminology usage (>0.90)
- Style consistency (>0.85)
General Capability Watch
- General QA (baseline -5%)
- Math capability (baseline -15% max)
- Reasoning tasks (baseline -10%)
Retraining Triggers
Architecture-Specific Drift Scenarios
🔍 RAG-Specific Drift Scenarios
| Scenario | Symptoms | Root Cause |
|---|---|---|
| Corpus Staleness | Answer relevance declining | Documents outdated |
| Embedding Drift | Retrieval precision drops | New query patterns |
| Chunk Issues | Faithfulness decreasing | Poor chunking for new docs |
| Vector DB Degradation | Retrieval latency spiking | Index optimization needed |
🤖 Agent-Specific Drift Scenarios
| Scenario | Symptoms | Root Cause |
|---|---|---|
| Tool Reliability Decay | Increasing timeout errors | External API degradation |
| Planning Inefficiency | More steps to complete tasks | Model quality drop |
| Context Saturation | Completion quality drops | Agent memory too full |
| Prompt Injection | Boundary violations spike | Security exploit attempts |
Cohort-Based Monitoring Dimensions
| Dimension | Segmentation | Why Monitor | Example Insight |
|---|---|---|---|
| User Geography | By region/country | Detect regional issues | APAC latency 3x higher due to CDN config |
| User Type | Free vs Premium | Segment-specific quality | Premium users see 10% better accuracy |
| Query Complexity | Simple vs Complex | Identify capability limits | Multi-step queries fail 40% more |
| Time of Day | Peak vs Off-peak | Resource contention | Quality drops 15% during peak hours |
| Platform | Web vs Mobile | Interface issues | Mobile truncation causes 20% errors |
Advanced Monitoring Techniques
2.3 AI/ML Observability - Understanding Why
💡 The Shift: Monitoring asks "What happened?" Observability asks "Why did it happen, and how can I understand what's happening inside?"
Observability is about understanding system behavior from external outputs. In AI/ML systems, this means being able to diagnose complex issues by analyzing traces, logs, and metrics across multiple layers.
| Aspect | Monitoring | Observability |
|---|---|---|
| Focus | Known failure modes | Unknown failure modes |
| Approach | Threshold-based alerts | Exploratory analysis |
| Questions | "Is it broken?" | "Why is it broken?" |
| Data | Pre-defined metrics | Rich, contextual traces |
| Use Case | Alerting on degradation | Root cause investigation |
The Six Layers of AI/ML Observability
Complete observability requires visibility across multiple layers of the stack:
| Layer | Focus Area | Key Questions | Example Insights |
|---|---|---|---|
| L1: Infrastructure | Logs & Traces | "Is the engine running?" | Response time 5s, GPU at 95% |
| L2: Model Performance | ML/AI Metrics | "How accurate are we?" | Accuracy 78% (baseline: 85%) |
| L3: Data Quality | Input Validation | "Is the fuel clean?" | 15% queries have malformed JSON |
| L4: Explainability | Decision Logic | "Why this prediction?" | Feature X drove 80% of decision |
| L5: Ethics/Security | Governance | "Are we operating safely?" | Bias detected in age group 55+ |
| L6: Business Impact | ROI & Value | "Reaching goals efficiently?" | Cost $0.45 vs target $0.30 |
80% of issues can be diagnosed with Layers 1-3 (Infrastructure + Performance + Data).
However, the remaining 20% (Layers 4-6) are often the most critical: bias issues can destroy brand reputation, poor business impact can kill the entire project, and unexplainable decisions can prevent adoption.
Detailed Layer Breakdown
🔧 Layer 1: Technical Infrastructure (Logs & Traces Level)
What to Observe:
- System health, resource utilization, error patterns
- Inference logs (request/response pairs)
- Server errors and exceptions
- Resource metrics (CPU, GPU, memory)
- API latency breakdown
Use Cases & Tools:
- Use: Debugging infrastructure, capacity planning
- Tools: OpenTelemetry, Datadog, New Relic
🤖 Layer 2: Model Performance (ML/AI Level)
What to Observe:
- AI quality metrics, degradation patterns
- Accuracy, precision, recall, F1-score
- Model-specific metrics (BLEU, ROUGE)
- Data drift detection
- Model degradation and anomaly detection
Use Cases & Tools:
- Use: Retraining detection, A/B testing
- Tools: MLflow, Weights & Biases, TensorBoard
📊 Layer 3: Data Quality (Data Level)
What to Observe:
- Input data characteristics and validity
- Input vs training distribution
- Missing values, noise, anomalies
- Feature drift and statistical tests
- Data completeness and format validation
Use Cases & Tools:
- Use: Preventing "garbage in, garbage out"
- Tools: Great Expectations, Evidently AI, Deepchecks
💡 Layer 4: Explainability & Fairness (Decision Level)
What to Observe:
- How and why decisions are made
- Feature attributions (SHAP, LIME)
- Bias detection across demographics
- Fairness metrics and equitable outcomes
- Decision transparency and interpretability
Use Cases & Tools:
- Use: Building trust, debugging predictions, compliance
- Tools: SHAP, LIME, Fairlearn, AI Fairness 360
🛡️ Layer 5: Ethics & Security (Governance Level)
What to Observe:
- Compliance, privacy, and security
- Privacy compliance (GDPR, anonymization)
- Security monitoring (adversarial attacks)
- Ethical AI guidelines adherence
- Responsible AI practices validation
Use Cases & Tools:
- Use: Regulatory compliance, risk management
- Tools: Microsoft Presidio, AWS Macie, custom frameworks
🎯 Layer 6: Business Impact (Value Level)
What to Observe:
- Real-world impact and ROI
- Business KPIs (conversion, satisfaction, revenue)
- Cost tracking and ROI measurement
- User engagement metrics
- Strategic alignment validation
Use Cases & Tools:
- Use: Proving AI value, budget justification
- Tools: Custom dashboards, BI tools (Tableau, PowerBI)
💡 Key Principle
Start with Layers 1-3 for quick wins, but don't neglect Layers 4-6 for long-term success. Problems can originate anywhere, and symptoms in one layer often have root causes in another. The richness of information across all layers is what makes you proactive rather than reactive.
Architecture-Specific Observability Deep Dive
RAG System Observability
RAG systems require tracing through multiple stages (query → embedding → retrieval → context assembly → generation):
| Pipeline Stage | What to Trace | What to Log | Common Root Causes |
|---|---|---|---|
| Query Processing | Query normalization, intent extraction | Raw query, cleaned query, detected intent | Encoding issues, unsupported languages |
| Embedding | Vector generation process | Model version, embedding dimensions, latency | Model mismatch, API throttling |
| Retrieval | Search execution, ranking | Retrieved chunks, scores, sources, latency | Poor index quality, semantic mismatch |
| Context Assembly | Chunk selection and ordering | Token count, chunk order, metadata | Inefficient chunking, too many results |
| Generation | LLM invocation | Prompt template, parameters, response | Wrong parameters, prompt injection |
| End-to-End | Complete flow | Total latency, cost, success/failure | Bottleneck identification |
Practical RAG Observability Example:
Agent System Observability
Agents make autonomous decisions across tools and reasoning steps. Observability must capture the decision chain:
| Component | What to Trace | What to Log | Common Root Causes |
|---|---|---|---|
| Task Understanding | Intent parsing, parameter extraction | User request, parsed goal, parameters | Ambiguous requests, poor parsing |
| Planning | Reasoning steps, plan generation | Planned steps, alternatives considered | Inefficient planning algorithm |
| Tool Selection | Decision logic, available tools | Tools considered, selection rationale, chosen tool | Ambiguous tool descriptions |
| Tool Execution | API calls, parameters, responses | Input, output, latency, errors | External API reliability issues |
| State Management | Memory updates, context | Working memory, long-term storage | Poor memory management |
| Error Recovery | Retry logic, fallbacks | Failure reason, retry attempts, outcome | Missing termination conditions |
Practical Agent Observability Example:
Fine-tuned Model Observability
Fine-tuned models need dual-track observability: domain performance AND general capability preservation. Must detect catastrophic forgetting early.
| Capability Track | What to Trace | What to Log | Common Root Causes |
|---|---|---|---|
| Domain Performance | Task-specific accuracy | Predictions vs ground truth, domain metrics | Domain drift, concept evolution |
| General Capabilities | Baseline NLP tasks | QA, reasoning, math, language | Catastrophic forgetting |
| Input Distribution | Query patterns | Topic distribution, complexity | Deployment scope creep |
| Output Consistency | Style and format | Format adherence, tone consistency | Fine-tuning effect fading |
| Comparative Baseline | vs Base model | Performance lift, cost savings | Model degradation |
Practical Fine-tuned Model Observability Example:
Advanced Observability Techniques
Beyond basic tracing, modern AI systems benefit from sophisticated observability approaches. Here are five advanced techniques to enhance your observability capabilities:
1️⃣ Distributed Tracing for Multi-Component Systems
For complex architectures (RAG + Agents, or chained agents), trace across components:
2️⃣ Anomaly Detection with Machine Learning
Use statistical models to automatically detect unusual patterns:
| Technique | What It Detects | Example | When to Use |
|---|---|---|---|
| Isolation Forest | Multivariate anomalies | Normal latency + high cost + low quality together | Complex patterns |
| Time Series Forecasting | Deviation from predictions | Predicted accuracy 0.85, actual 0.68 | Temporal metrics |
| Clustering | New behavior patterns | New cluster of "PDF parsing errors" | Grouping issues |
| Change Point Detection | Sudden shifts | Performance drop exactly after deployment | Event correlation |
3️⃣ Explainability Integration
Connect observability to explainability for complete understanding:
4️⃣ Continuous Feedback Loops
Connect observability data back to improvement cycles:
Examples of feedback loops:
Self-Improving Cycle Example:
- Day 1: Observability detects "30% failures on queries >100 tokens"
- Day 2: Root cause: Token limit issues with long queries
- Day 3: Evaluation tests query truncation strategies
- Day 4: Monitoring adds "query length distribution" metric
- Day 5: Observability now includes query length in all traces
- Day 30: System automatically handles long queries + alerts on new patterns
Result: Each issue discovered makes the system smarter
5️⃣ LLM-as-Judge for Automated Root Cause Analysis
Today's LLM-based evaluators can access entire traces to provide intelligent diagnostic insights beyond simple scoring.
How it works:
- Input: Complete trace with all spans, logs, and metrics
- Analysis: LLM evaluates the entire request flow contextually
- Output: Structured diagnostic feedback with identified failure points
Benefits:
- Automated diagnostics (no manual trace inspection)
- Context-aware analysis
- Natural language explanations
- Pattern recognition from historical traces
Integration: Monitoring alerts → Trigger LLM-as-Judge analysis → LLM findings → Update evaluation criteria and monitoring metrics → Continuous learning
Bonus: Synthetic Transaction Monitoring
Proactively test system behavior with predefined scenarios:
| Scenario Type | What It Tests | Frequency | Example |
|---|---|---|---|
| Golden Path | Normal operation | Every 5 min | "What's the weather?" → Should succeed |
| Edge Cases | Boundary conditions | Every 30 min | Very long query (5000 chars) → Should handle gracefully |
| Known Failures | Historical bugs | Every hour | Query that caused crash last month → Should now work |
| Security Tests | Malicious patterns | Every hour | Prompt injection attempt → Should be blocked |
- 1Distributed Tracing: Trace requests across RAG/Agent components with Trace IDs, identify bottlenecks (e.g., "Vector Search: 14% of total time")
- 2Anomaly Detection with ML: Isolation Forest for multivariate anomalies, Time Series Forecasting for deviation detection, Clustering for new behavior patterns
- 3Explainability Integration: Connect SHAP values to observability traces, understand feature contributions alongside system performance
- 4LLM-as-Judge Diagnostics: Use LLMs to analyze traces and suggest root causes automatically - "Root cause: Retrieval stage returned chunks with relevance score <0.65"
- 5Continuous Feedback Loops: Detected failures → New test cases, Identified weak areas → Targeted data collection, New anomalies → Updated alert thresholds
Today's LLM-based evaluators can access entire traces to provide intelligent diagnostic insights:
- Automated diagnostics: No manual trace inspection for common issues
- Context-aware analysis: Understands relationships between components
- Natural language explanations: Makes root causes accessible to non-experts
- Pattern recognition: Learns from historical traces to identify recurring issues
2.4 Putting It All Together - The Transversal Nature
Now that we've explored each pillar individually, let's acknowledge the elephant in the room: these boundaries are intentionally fuzzy. The same metric serves different purposes across pillars.
📊 Evaluation asks: "What should good look like?"
📈 Monitoring asks: "Are we still good?"
🔍 Observability asks: "Why are we (not) good?"
The Overlap Matrix
| Metric/Activity | Evaluation | Monitoring | Observability |
|---|---|---|---|
| Context Precision | ✅ Sets quality standard | ✅ Tracks degradation | ✅ Diagnoses retrieval issues |
| Latency | ✅ Establishes acceptable range | ✅ Primary: Real-time tracking | ✅ Traces bottlenecks |
| Hallucination Rate | ✅ Primary: Measures accuracy | ✅ Alerts on increase | ✅ Identifies trigger patterns |
| Data Drift | ✅ Defines expected distribution | ✅ Primary: Detects changes | ✅ Analyzes impact |
| User Satisfaction | ✅ Sets target scores | ✅ Tracks trends | ✅ Correlates with system behavior |
How Metrics Flow Through the System
Example: Context Precision in a RAG System
- As Evaluation: "Our system achieves 0.85 context precision" (baseline setting)
- As Monitoring: "Alert! Context precision dropped to 0.65" (deviation detection)
- As Observability: "Low precision traced to new document format causing chunking issues" (root cause)
- Back to Evaluation: "New chunking strategy improves to 0.90" (validation)
- Enhanced Monitoring: "New metric added: chunk size distribution" (improvement)
Don't get paralyzed by trying to perfectly categorize every metric or tool. Instead:
- Start with Evaluation to establish what success means
- Implement Monitoring to know when you deviate from success
- Add Observability to understand and fix deviations
- Iterate using insights from all three to continuously improve
Part III: Maturity Model
3.1 The Journey to Evaluation Excellence
Evaluation Maturity Levels
- 1Level 1: Ad-hoc 🔴 - Manual testing, no standards, reactive fixes. Getting started.
- 2Level 2: Systematic 🟡 - Test suites, basic metrics, pre-deployment checks. Building foundation.
- 3Level 3: Automated 🔵 - CI/CD integration, LLM-as-Judge, regular eval. Scaling up.
- 4Level 4: Continuous 🟢 - Production sampling, real-time metrics, feedback loops. Production excellence.
- 5Level 5: Self-Improving ⭐ - Auto-optimization, predictive quality, closed-loop RLHF. Industry leading.
Maturity Assessment Checklist
✅ Level 1: Ad-hoc (Getting Started)
🔄 Level 2: Systematic (Building Foundation)
📊 Level 3: Automated (Scaling Up)
🚀 Level 4: Continuous (Production Excellence)
⭐ Level 5: Self-Improving (Industry Leading)
3.2 Common Pitfalls and How to Avoid Them
The Pitfall Chain
These pitfalls often lead to each other, creating a vicious cycle:
Software-only observability → No production feedback → Missing baselines → Insights without action → Static test sets → Over-automation blind spots → (cycle repeats)
| 🚨 Pitfall | 📝 What Happens | ✅ How to Avoid | 💡 Example |
|---|---|---|---|
| Software-only observability | Missing AI-specific issues | Implement all 6 observability layers | Team tracks latency but misses hallucination patterns |
| Eval without prod feedback | Lab metrics ≠ real perf | Continuous evaluation in prod | 95% accuracy in testing, 70% with real users |
| Monitoring w/o baselines | Unknown "normal" state | Establish baselines in eval | Alerts fire constantly because thresholds are guesses |
| Observability w/o action | Insights but no fixes | Create action playbooks | Detailed traces showing issues but no fix process |
| Static test sets | Drift from reality | Continuously add prod examples | Test set from 6 months ago doesn't reflect current usage |
| Over-relying on automation | LLM judges have blind spots | Regular human eval (5-10%) | LLM-as-Judge misses subtle bias issues |
| Ignoring cost-quality tradeoffs | Optimizing quality bankrupts project | Track quality/cost ratio | 2% accuracy gain costs 10x more |
Part IV: Implementation Guide
4.1 When to Use Which Architecture
Start with your primary need and follow the decision path:
| If You Need... | Best Architecture | Key Evaluation Focus | Common Pitfalls |
|---|---|---|---|
| Frequently updated knowledge | RAG | Retrieval quality, source attribution | Over-engineering retrieval |
| Domain-specific expertise | Fine-tuning | Domain accuracy, style consistency | Catastrophic forgetting |
| Task automation | Agents | Tool usage accuracy, task completion | Unreliable tool execution |
| Cost-effective accuracy | RAG + Prompting | Context usage, response quality | Prompt brittleness |
| Maximum control | Fine-tuning + RAG | Both retrieval and generation | Complexity explosion |
| Complex workflows | Multi-agent systems | Inter-agent coordination | Debugging difficulty |
Part V: Troubleshooting Guide
5.1 Common Issues and Solutions
When an issue is detected, identify the type first:
| 🔍 Symptom | 🎯 Likely Cause | 🔬 How to Investigate | ✅ Solution |
|---|---|---|---|
| Hallucinations increasing | Poor retrieval quality | Check context relevance scores | • Improve chunking strategy • Enhance embedding model • Add retrieval validation |
| Slow responses | Oversized contexts | Trace token usage per request | • Optimize context window • Implement compression • Use streaming responses |
| Wrong tool usage | Unclear tool descriptions | Review tool selection logs | • Improve tool descriptions • Add few-shot examples • Implement tool validation |
| Inconsistent outputs | High temperature or prompt issues | Check generation parameters | • Lower temperature • Improve prompt clarity • Add output validators |
| Rising costs | Inefficient token usage | Monitor token consumption patterns | • Optimize prompts • Cache common responses • Use smaller models where possible |
| User dissatisfaction | Misaligned with user needs | Analyze feedback patterns | • Update evaluation criteria • Refine success metrics • Implement RLHF |
5.2 The Feedback Loop in Action
The Continuous Improvement Cycle
- 11. Evaluation sets baseline: "Good = 0.85 faithfulness"
- 22. Monitoring detects deviation: "Alert! Faithfulness at 0.65"
- 33. Observability finds root cause: "New doc format breaking chunking"
- 44. Solution identified: "Update chunking strategy"
- 55. Re-Evaluation validates fix: "New strategy: 0.90 faithfulness"
- 66. Update System: Enhanced monitoring metrics, better traces, updated baselines
This creates an ascending spiral of improvement, not just a loop! Each cycle:
Conclusion: Your Path Forward
🎯 Key Takeaways
1. The Three Pillars Are Inseparable: Evaluation, Monitoring, and Observability work together to create trustworthy AI systems. You need all three.
2. Architecture Matters: RAG, Agents, and Fine-tuned models each require specific evaluation approaches. One size does not fit all.
3. Continuous Evaluation is Non-Negotiable: Unlike traditional software, AI systems require constant evaluation in production, not just before deployment.
4. Start Simple, Evolve Continuously: Begin with Level 1 maturity and progressively build capabilities. Perfect is the enemy of good.
5. Metrics Are Transversal: The same metric serves different purposes across pillars - embrace this overlap rather than fighting it.
💡 Final Thoughts
Building trustworthy GenAI systems isn't about choosing between Evaluation, Monitoring, or Observability - it's about orchestrating all three into a symphony of continuous improvement. Each pillar strengthens the others, creating a system that not only works but gets better over time.
Every production issue is a learning opportunity.
With proper evaluation, monitoring, and observability, you transform problems into progress, bugs into insights, and failures into features. The journey from reactive firefighting to proactive improvement starts with understanding these three pillars.
Questions? Feedback? Disagreements? Please share your thoughts - this field evolves through collective learning.
Comments
No comments yet. Be the first to comment!