Guide pédagogique de l'observabilité, l'évaluation et le monitoring GenAI

Débloquez une IA de confiance : Maîtrisez l'évaluation, le monitoring et l'observabilité. Découvrez pourquoi la pensée DevOps échoue pour l'IA et comment un modèle "hélicoïdal" élève vos systèmes. Arrêtez de réagir aux problèmes ; améliorez proactivement votre IA, détectez les problèmes tôt et éliminez les boîtes noires.
Débloquez une IA de confiance : Maîtrisez l'évaluation, le monitoring et l'observabilité. Découvrez pourquoi la pensée DevOps échoue pour l'IA et comment un modèle "hélicoïdal" élève vos systèmes. Arrêtez de réagir aux problèmes ; améliorez proactivement votre IA, détectez les problèmes tôt et éliminez les boîtes noires.
Construire les fondations d'une IA de confiance
Ce guide définit et explique ce qui est nécessaire pour établir les fondations complètes d'une IA de confiance : Évaluation IA, Monitoring IA et Observabilité IA.
Questions critiques résolues
Partie I : Dissiper le brouillard - Les fondations
1.1 Le problème de confusion
Beaucoup de confusion existe autour des termes monitoring IA/ML, observabilité IA/ML, et évaluation IA/ML.
Idées reçues courantes
- "L'observabilité et le monitoring sont la même chose"
- "L'observabilité en IA/ML, c'est le tracing."
- "L'observabilité, c'est juste du monitoring avec plus de métriques."
- "L'évaluation, c'est juste du monitoring mais avant le déploiement."
Cela mène à de la confusion, des débats, des problèmes de périmètre, beaucoup d'énergie perdue, et parfois même l'abandon d'initiatives. Clarifions ces termes une fois pour toutes.
1.2 Les trois piliers - Définitions simples
Définitions détaillées
1.3 Le changement de paradigme - Pourquoi ces trois piliers sont essentiels
Logiciel traditionnel
- Logique déterministe
- Entrée X → Sortie Y, toujours
- Boucle DevOps (∞)
- Corriger les bugs et revenir à l'état initial
Systèmes IA/ML
- Comportement probabiliste
- Entrée X → Sortie Y probable
- Modèle Hélicoïdal IA/ML (🌀)
- Chaque itération élève le système
Des boucles DevOps au modèle hélicoïdal IA/ML
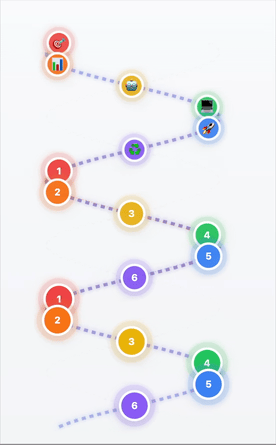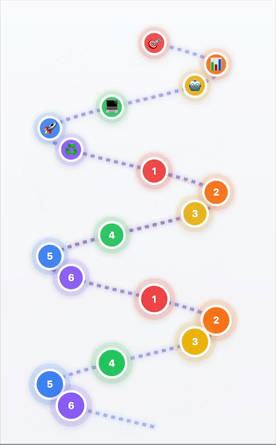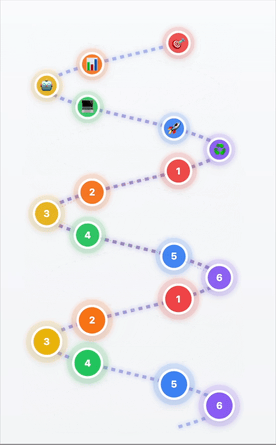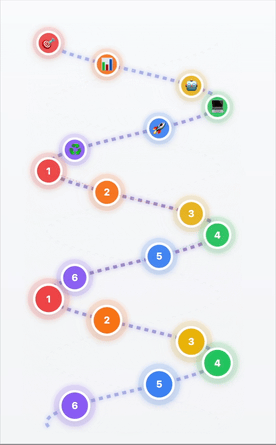
- 1Cadrage et définition du problème → Que résolvons-nous ?
- 2Investigation et préparation des données → Données de qualité = IA de qualité
- 3Sélection et adaptation du modèle → Le bon outil pour la tâche
- 4Développement applicatif → Construire la solution
- 5Déploiement et mise à l'échelle → Passer en production
- 6Amélioration continue → Apprendre et progresser
Un exemple concret : La spirale ascendante
Considérez un chatbot qui commence à halluciner :
- Le monitoring alerte :
La précision est passée de 92% à 78%(Détection) - L'observabilité trace :
Les hallucinations corrèlent avec les documents découpés > 512 tokens(Cause racine) - L'évaluation mesure :
La nouvelle stratégie de découpage améliore la fidélité de 0.7 à 0.9(Validation)
Point clé : Vous ne faites pas que "corriger" le bug de découpage. Vous avez appris sur les tailles de chunks optimales, améliorant votre préparation des données, vos critères d'évaluation, vos seuils de monitoring et vos traces d'observabilité.
1.4 Observabilité : La distinction cruciale
Pourquoi votre observabilité DevOps ne suffit pas pour l'IA : Les systèmes IA ont des défis uniques (non-déterministes, dépendants des données, etc.) que le monitoring traditionnel ne peut pas capturer.
| Aspect | Observabilité IT traditionnelle | Observabilité IA/ML |
|---|---|---|
| Logs | Erreurs applicatives, requêtes, événements système | Logs d'inférence, erreurs de prédiction, entrées/sorties du modèle |
| Traces | Suivi d'une requête à travers plusieurs services (microservices, APIs) | Suivi du flux de données : collecte → prétraitement → prédiction (lignage) |
| Métriques techniques | Temps de réponse, disponibilité, usage CPU/GPU | Latence d'inférence, coût d'exécution, saturation GPU |
| Métriques métier | Taux de succès API, conformité SLA | KPIs alignés métier (fraudes détectées, ventes augmentées, erreurs médicales évitées) |
| Qualité des données | À peine couverte, sauf validation basique | Vérification de la distribution des features, valeurs manquantes, dérive des données |
| Performance du modèle | Non applicable | Précision, rappel, score F1, AUC, détection de dégradation du modèle |
| Biais et équité | Non pertinent | Détection de biais (genre, âge, origine), équité des prédictions |
| Explicabilité | Non pertinent | Techniques comme SHAP, LIME pour comprendre pourquoi le modèle prédit X |
| Alertes | Erreurs système, pannes | Dégradation de performance, anomalies de données, dérive du modèle |
| Objectif final | Assurer la fiabilité de l'infrastructure/application | Assurer la fiabilité, la transparence et l'impact positif des modèles IA |
Partie II : L'exploration en profondeur - Comprendre chaque pilier
2.1 Évaluation IA/ML - Définir le standard
Considérez l'évaluation IA/ML comme l'élément qui définit le succès de vos modèles. Il s'agit d'établir des critères clairs et objectifs pour ce que signifie "bon" dans le contexte de votre application spécifique.
Niveaux d'évaluation
- 1Niveau 0 : Fondation (Données) - Mauvaises données = mauvais résultats quelle que soit l'architecture. Garbage in = Garbage out
- 2Niveau 1 : Métriques simples - Compréhension de base : taux de succès des tâches, précision des réponses, fréquence des erreurs
- 3Niveau 2 : Évaluation par composant - RAG : Retrieval vs Génération | Agents : Sélection d'outils vs Exécution vs Planification
- 4Niveau 3 : Multi-dimensionnel - La qualité est multifacette : fidélité, pertinence, cohérence, vérifications de toxicité
- 5Niveau 4 : Évaluation continue - Performance en labo ≠ Performance en production. Évaluation en ligne avec de vrais utilisateurs
Types d'évaluation
Timing : Hors ligne vs En ligne
Méthode : Automatisée vs Humaine
Contrairement au ML traditionnel où vous avez des labels clairs (chat vs chien), l'évaluation GenAI est fondamentalement différente - souvent aucune réponse "correcte" unique n'existe.
La couche fondation - Évaluation des données
La règle des 80/20
Vérifications universelles de qualité des données
Focus spécifique à l'architecture
| Type de problème | Systèmes RAG | Systèmes Agent | Fine-tuning |
|---|---|---|---|
| Problèmes de format | PDFs avec tableaux mal extraits | Formats de sortie d'outils incohérents | Données d'entraînement en formats mixtes |
| Info manquante | Pas de métadonnées (auteur, date) | Descriptions d'outils manquant de params | Labels ou features manquants |
| Données conflictuelles | Plusieurs versions de docs se contredisent | Outils avec objectifs qui se chevauchent | Contamination train/test |
| Données sensibles | PII dans les documents | Clés API dans configs d'outils | Données personnelles dans le jeu d'entraînement |
Évaluation approfondie par architecture

Évaluation des systèmes RAG
Évaluation du découpage de documents
| Stratégie | Qualité | Temps setup | Idéal pour |
|---|---|---|---|
| 📏 Taille fixe | ⭐ | 5 min | Logs, texte uniforme simple |
| 🔄 Récursif | ⭐⭐⭐ | 30 min | Code, Markdown, contenu structuré |
| 🧠 Sémantique | ⭐⭐⭐⭐ | 2-3 hrs | Articles, blogs, texte narratif |
| 🏗️ Structurel | ⭐⭐⭐⭐⭐ | 1-2 jours | Rapports, PDFs, docs complexes |
| 🤖 Agentique | ⭐⭐⭐⭐⭐ | 1 sem+ | Contenu stratégique, mission-critique |
Le framework de la Triade RAG
Les systèmes RAG nécessitent l'évaluation de trois composants interconnectés :
| Composant | Métrique | Cible | Pourquoi critique |
|---|---|---|---|
| Retrieval | Précision du contexte | 0.85-1.0 | Mauvais retrieval → hallucinations |
| Retrieval | Rappel du contexte | 0.80-1.0 | Contexte manquant → réponses incomplètes |
| Génération | Fidélité | 0.85-1.0 | Empêche les inventions |
| End-to-end | Exactitude réponse | 0.80-1.0 | Métrique de valeur métier |
Performance de la base vectorielle
Cibles de performance :
- • Latence requête : <100ms
- • Débit : >100 QPS
- • Recall@k : >0.90
- • Mémoire : <4GB par 1M vecteurs
Sélection d'algorithme :
- • HNSW : Meilleur polyvalent (commencer ici)
- • Faiss IVF : Très grande échelle
- • ScaNN : Besoins haute performance
- • ANNOY : Données statiques uniquement
Évaluation des systèmes Agent
Tous les agents ne sont pas égaux. L'approche d'évaluation doit correspondre au niveau d'autonomie de l'agent :
Les agents nécessitent une approche à deux niveaux : Niveau Composant (débogage) et End-to-End (expérience utilisateur).
| Aspect | Métrique | Critère succès | Technique |
|---|---|---|---|
| Sélection outil | Exactitude outil | >0.90 | Correspondance déterministe |
| Paramètres outil | Précision paramètres | >0.95 | Validation de schéma |
| Efficacité outil | Usage redondant | <10% overhead | Analyse de chemin |
| Qualité planif. | Cohérence du plan | >0.85 | LLM-as-Judge |
| Complétion tâche | Taux de succès | >0.85 | Binaire + crédit partiel |
| Récupération erreur | Succès récupération | >0.75 | Test injection de fautes |
Métriques clés
Vérifications sécurité
Frameworks d'évaluation d'agents
| Framework | Focus principal | Quand utiliser |
|---|---|---|
| DeepEval | Tests complets | Développement & CI/CD |
| AgentBench | Benchmarking multi-environnement | Évaluation comparative |
| Phoenix (Arize) | Observabilité & Tracing | Débogage production |
| LangSmith | Cycle de vie complet | Workflows entreprise |
Évaluation des modèles fine-tunés
Le fine-tuning est le bon choix quand vous avez besoin d'une expertise de domaine profonde, d'un ton/style cohérent, ou d'une latence réduite qui ne peut être atteinte par le prompting seul. Cependant, c'est coûteux en calcul et nécessite une expertise significative.
Matrice de décision : Devriez-vous fine-tuner ?
| Critère | Seuil | Justification |
|---|---|---|
| Volume requêtes | > 100 000/mois | Volume élevé justifie coûts entraînement |
| Spécificité domaine | < 30% overlap vocab | Modèles généraux manquent de connaissance domaine |
| Cohérence ton | > 90% requis | Voix de marque critique |
| Exigences latence | < 500ms | Besoin déploiement edge |
| Disponibilité données | > 10 000 exemples qualité | Suffisant pour entraînement efficace |
4+ critères remplis : Fortement recommandé | 2-3 remplis : Considérer attentivement | 0-1 rempli : Utiliser RAG ou prompting
Oubli catastrophique - Le tueur silencieux
Dimensions d'évaluation critiques
Gain d'expertise domaine
Style & Capacité générale
Comparaison Fine-tuné vs Baseline
| Dimension | Baseline | Fine-tuné | Évaluation |
|---|---|---|---|
| Précision domaine | 72% | 89% | ✅ +17% amélioration |
| Tâches générales | 92% | 85% | ✅ -7% acceptable |
| Latence (p95) | 2.1s | 1.2s | ✅ -43% amélioration |
| Coût/1K requêtes | 0.15€ | 0.05€ | ✅ -67% économies |
| Cohérence style | 78% | 94% | ✅ +16% amélioration |
2.2 Monitoring IA/ML - Garder l'œil ouvert
📍 Important
Le monitoring consiste fondamentalement à surveiller les écarts par rapport à votre baseline. Pensez-y comme une comparaison continue entre le comportement attendu (baseline de l'évaluation) et le comportement réel (ce qui se passe en production).
Dimensions universelles du monitoring
| Dimension | Ce qu'elle suit | Pourquoi critique | Métriques universelles |
|---|---|---|---|
| Performance | Vitesse et fiabilité système | Expérience utilisateur, contrôle coûts | Latence (P50, P95, P99), débit, taux d'erreur |
| Qualité | Précision des sorties IA | Valeur métier centrale | Taux succès tâche, scores qualité, satisfaction utilisateur |
| Stabilité | Cohérence dans le temps | Empêche dégradation silencieuse | Scores de dérive, métriques de variance, taux anomalies |
| Ressources | Coûts computationnels | Budget et scalabilité | Usage tokens, coûts API, utilisation GPU |
Les trois dérives
Détection : Tests statistiques (divergence KL, PSI), tendances performance, métriques vs baseline
Framework de sévérité des alertes
- 🟢 Info : Dans la plageLog seulement
- ⚠️ Warning : 10-20% déviationInvestiguer (4h)
- 🔴 Critique : >20% déviationUrgent (30min)
- 🚨 Urgence : Service downAppeler l'astreinte
Monitoring santé système (Universel)
| Métrique | Plage OK | Warning | Critique | Pourquoi monitorer |
|---|---|---|---|---|
| Disponibilité API | 99.9%+ | <99.5% | <99% | Fiabilité service |
| Latence P50 | <1s | >1.5s | >2s | Expérience utilisateur |
| Latence P95 | <2s | >3s | >4s | Performance pire cas |
| Taux erreur | <1% | >2% | >5% | Stabilité système |
| Usage tokens | Conforme budget | 80% budget | 90% budget | Contrôle coûts |
Monitoring spécifique par architecture
🔍 Points de contrôle monitoring RAG
Requête & Retrieval
- Distribution longueur requête (±30% baseline)
- Taux hors-domaine (<5%)
- Précision/rappel contexte (0.85+)
- Latence retrieval (<500ms)
- Taux zéro résultat (<5%)
Génération & Utilisateur
- Fidélité (0.85+)
- Pertinence réponse (0.85+)
- Satisfaction utilisateur (>4.0/5)
- Taux question de suivi (<15%)
- Coût par requête (budget)
🤖 Monitoring Agent
Métriques tâche & outil
- Taux succès tâche (>0.85)
- Précision sélection outil (>0.90)
- Exactitude paramètres (>0.95)
- Appels outil redondants (<10%)
Sécurité & Planification
- Violations autorisation (0)
- Dépassements limites (<1%)
- Efficacité plan (<20% overhead)
- Détection boucles (0)
🎯 Monitoring modèle fine-tuné
Performance domaine
- Précision domaine (baseline -5%)
- Usage terminologie (>0.90)
- Cohérence style (>0.85)
Surveillance capacité générale
- QA général (baseline -5%)
- Capacité math (baseline -15% max)
- Tâches raisonnement (baseline -10%)
Déclencheurs de réentraînement
Techniques avancées de monitoring
2.3 Observabilité IA/ML - Comprendre le pourquoi
💡 Le changement : Le monitoring demande "Que s'est-il passé ?" L'observabilité demande "Pourquoi cela s'est-il passé, et comment puis-je comprendre ce qui se passe à l'intérieur ?"
L'observabilité consiste à comprendre le comportement du système à partir des sorties externes. Dans les systèmes IA/ML, cela signifie être capable de diagnostiquer des problèmes complexes en analysant les traces, logs et métriques à travers plusieurs couches.
| Aspect | Monitoring | Observabilité |
|---|---|---|
| Focus | Modes de défaillance connus | Modes de défaillance inconnus |
| Approche | Alertes basées sur seuils | Analyse exploratoire |
| Questions | "Est-ce cassé ?" | "Pourquoi est-ce cassé ?" |
| Données | Métriques prédéfinies | Traces riches et contextuelles |
| Cas d'usage | Alerter sur dégradation | Investigation cause racine |
Les six couches de l'observabilité IA/ML
Une observabilité complète nécessite une visibilité à travers plusieurs couches de la stack :
| Couche | Zone de focus | Questions clés | Exemples d'insights |
|---|---|---|---|
| C1 : Infrastructure | Logs & Traces | "Le moteur tourne-t-il ?" | Temps réponse 5s, GPU à 95% |
| C2 : Performance modèle | Métriques ML/IA | "Quelle est notre précision ?" | Précision 78% (baseline : 85%) |
| C3 : Qualité données | Validation entrées | "Le carburant est-il propre ?" | 15% requêtes ont JSON malformé |
| C4 : Explicabilité | Logique décision | "Pourquoi cette prédiction ?" | Feature X a conduit 80% de la décision |
| C5 : Éthique/Sécurité | Gouvernance | "Opérons-nous en sécurité ?" | Biais détecté groupe âge 55+ |
| C6 : Impact métier | ROI & Valeur | "Atteignons-nous les objectifs ?" | Coût 0.45€ vs cible 0.30€ |
80% des problèmes peuvent être diagnostiqués avec les Couches 1-3 (Infrastructure + Performance + Données).
Cependant, les 20% restants (Couches 4-6) sont souvent les plus critiques : les problèmes de biais peuvent détruire la réputation de marque, un mauvais impact métier peut tuer tout le projet, et des décisions inexplicables peuvent empêcher l'adoption.
Décomposition détaillée des couches
🔧 Couche 1 : Infrastructure technique (Niveau Logs & Traces)
Quoi observer :
- Santé système, utilisation ressources, patterns d'erreur
- Logs d'inférence (paires requête/réponse)
- Erreurs serveur et exceptions
- Métriques ressources (CPU, GPU, mémoire)
- Décomposition latence API
Cas d'usage & Outils :
- Usage : Débogage infrastructure, planification capacité
- Outils : OpenTelemetry, Datadog, New Relic
🤖 Couche 2 : Performance modèle (Niveau ML/IA)
Quoi observer :
- Métriques qualité IA, patterns de dégradation
- Précision, rappel, score F1
- Métriques spécifiques modèle (BLEU, ROUGE)
- Détection dérive données
- Dégradation modèle et détection anomalies
Cas d'usage & Outils :
- Usage : Détection besoin réentraînement, tests A/B
- Outils : MLflow, Weights & Biases, TensorBoard
📊 Couche 3 : Qualité données (Niveau Données)
Quoi observer :
- Caractéristiques et validité des données d'entrée
- Distribution entrée vs entraînement
- Valeurs manquantes, bruit, anomalies
- Dérive features et tests statistiques
- Complétude données et validation format
Cas d'usage & Outils :
- Usage : Prévenir "garbage in, garbage out"
- Outils : Great Expectations, Evidently AI, Deepchecks
💡 Couche 4 : Explicabilité & Équité (Niveau Décision)
Quoi observer :
- Comment et pourquoi les décisions sont prises
- Attributions features (SHAP, LIME)
- Détection biais à travers démographies
- Métriques équité et résultats équitables
- Transparence décision et interprétabilité
Cas d'usage & Outils :
- Usage : Construire la confiance, déboguer prédictions, conformité
- Outils : SHAP, LIME, Fairlearn, AI Fairness 360
🛡️ Couche 5 : Éthique & Sécurité (Niveau Gouvernance)
Quoi observer :
- Conformité, vie privée et sécurité
- Conformité vie privée (RGPD, anonymisation)
- Monitoring sécurité (attaques adversariales)
- Adhésion aux guidelines IA éthique
- Validation pratiques IA responsable
Cas d'usage & Outils :
- Usage : Conformité réglementaire, gestion risques
- Outils : Microsoft Presidio, AWS Macie, frameworks custom
🎯 Couche 6 : Impact métier (Niveau Valeur)
Quoi observer :
- Impact réel et ROI
- KPIs métier (conversion, satisfaction, revenu)
- Suivi coûts et mesure ROI
- Métriques engagement utilisateur
- Validation alignement stratégique
Cas d'usage & Outils :
- Usage : Prouver la valeur IA, justification budget
- Outils : Dashboards custom, outils BI (Tableau, PowerBI)
💡 Principe clé
Commencez par les Couches 1-3 pour des gains rapides, mais ne négligez pas les Couches 4-6 pour le succès long terme. Les problèmes peuvent provenir de n'importe où, et les symptômes dans une couche ont souvent leurs causes racines dans une autre. C'est la richesse d'information à travers toutes les couches qui vous rend proactif plutôt que réactif.
Techniques avancées d'observabilité
Au-delà du tracing basique, les systèmes IA modernes bénéficient d'approches d'observabilité sophistiquées :
- 1Tracing distribué : Tracez les requêtes à travers les composants RAG/Agent avec des Trace IDs, identifiez les goulots d'étranglement (ex: "Recherche vectorielle : 14% du temps total")
- 2Détection d'anomalies par ML : Isolation Forest pour anomalies multivariées, prévision séries temporelles pour détection déviation, clustering pour nouveaux patterns comportementaux
- 3Intégration explicabilité : Connectez les valeurs SHAP aux traces d'observabilité, comprenez les contributions features en parallèle de la performance système
- 4Diagnostics LLM-as-Judge : Utilisez les LLMs pour analyser les traces et suggérer des causes racines automatiquement - "Cause racine : L'étape retrieval a renvoyé des chunks avec score pertinence <0.65"
- 5Boucles de feedback continues : Échecs détectés → Nouveaux cas de test, Zones faibles identifiées → Collecte données ciblée, Nouvelles anomalies → Seuils alertes mis à jour
Les évaluateurs basés LLM d'aujourd'hui peuvent accéder aux traces complètes pour fournir des insights diagnostiques intelligents :
- Diagnostics automatisés : Pas d'inspection manuelle des traces pour les problèmes courants
- Analyse contextuelle : Comprend les relations entre composants
- Explications en langage naturel : Rend les causes racines accessibles aux non-experts
- Reconnaissance de patterns : Apprend des traces historiques pour identifier les problèmes récurrents
2.4 Assembler le tout - La nature transversale
Maintenant que nous avons exploré chaque pilier individuellement, reconnaissons l'éléphant dans la pièce : ces frontières sont intentionnellement floues. La même métrique sert différents objectifs à travers les piliers.
📊 L'évaluation demande : "À quoi devrait ressembler le bon ?"
📈 Le monitoring demande : "Sommes-nous toujours bons ?"
🔍 L'observabilité demande : "Pourquoi sommes-nous (pas) bons ?"
La matrice de chevauchement
| Métrique/Activité | Évaluation | Monitoring | Observabilité |
|---|---|---|---|
| Précision contexte | ✅ Définit standard qualité | ✅ Suit la dégradation | ✅ Diagnostique problèmes retrieval |
| Latence | ✅ Établit plage acceptable | ✅ Principal : Suivi temps réel | ✅ Trace les goulots |
| Taux hallucination | ✅ Principal : Mesure précision | ✅ Alerte sur augmentation | ✅ Identifie patterns déclencheurs |
| Dérive données | ✅ Définit distribution attendue | ✅ Principal : Détecte changements | ✅ Analyse l'impact |
| Satisfaction utilisateur | ✅ Définit scores cibles | ✅ Suit les tendances | ✅ Corrèle avec comportement système |
Comment les métriques circulent dans le système
Exemple : Précision du contexte dans un système RAG
- En évaluation : "Notre système atteint 0.85 de précision contexte" (définition baseline)
- En monitoring : "Alerte ! Précision contexte tombée à 0.65" (détection déviation)
- En observabilité : "Faible précision tracée vers nouveau format document causant problèmes chunking" (cause racine)
- Retour à l'évaluation : "Nouvelle stratégie chunking améliore à 0.90" (validation)
- Monitoring amélioré : "Nouvelle métrique ajoutée : distribution taille chunks" (amélioration)
Ne vous paralysez pas à essayer de catégoriser parfaitement chaque métrique ou outil. À la place :
- Commencez par l'évaluation pour établir ce que signifie le succès
- Implémentez le monitoring pour savoir quand vous déviez du succès
- Ajoutez l'observabilité pour comprendre et corriger les déviations
- Itérez en utilisant les insights des trois pour améliorer continuellement
Partie III : Modèle de maturité
3.1 Le parcours vers l'excellence en évaluation
Niveaux de maturité en évaluation
- 1Niveau 1 : Ad-hoc 🔴 - Tests manuels, pas de standards, corrections réactives. Début du parcours.
- 2Niveau 2 : Systématique 🟡 - Suites de tests, métriques basiques, vérifications pré-déploiement. Construction des fondations.
- 3Niveau 3 : Automatisé 🔵 - Intégration CI/CD, LLM-as-Judge, éval régulière. Passage à l'échelle.
- 4Niveau 4 : Continu 🟢 - Échantillonnage production, métriques temps réel, boucles feedback. Excellence production.
- 5Niveau 5 : Auto-améliorant ⭐ - Auto-optimisation, qualité prédictive, RLHF boucle fermée. Leader industrie.
Checklist d'évaluation de maturité
✅ Niveau 1 : Ad-hoc (Début)
🔄 Niveau 2 : Systématique (Construction fondations)
📊 Niveau 3 : Automatisé (Passage à l'échelle)
🚀 Niveau 4 : Continu (Excellence production)
⭐ Niveau 5 : Auto-améliorant (Leader industrie)
3.2 Pièges courants et comment les éviter
La chaîne des pièges
Ces pièges mènent souvent les uns aux autres, créant un cercle vicieux :
Observabilité logicielle uniquement → Pas de feedback production → Baselines manquantes → Insights sans action → Jeux de test statiques → Angles morts sur-automatisation → (cycle se répète)
| 🚨 Piège | 📝 Ce qui se passe | ✅ Comment éviter | 💡 Exemple |
|---|---|---|---|
| Observabilité logicielle uniquement | Problèmes spécifiques IA manqués | Implémenter les 6 couches observabilité | Équipe suit latence mais rate patterns hallucination |
| Éval sans feedback prod | Métriques labo ≠ perf réelle | Évaluation continue en prod | 95% précision en test, 70% avec vrais utilisateurs |
| Monitoring sans baselines | État "normal" inconnu | Établir baselines en éval | Alertes se déclenchent constamment car seuils sont des suppositions |
| Observabilité sans action | Insights mais pas de corrections | Créer playbooks d'action | Traces détaillées montrant problèmes mais pas de processus fix |
| Jeux de test statiques | Dérive par rapport à la réalité | Ajouter continuellement exemples prod | Jeu de test d'il y a 6 mois ne reflète pas usage actuel |
| Sur-dépendance automatisation | Juges LLM ont angles morts | Éval humaine régulière (5-10%) | LLM-as-Judge rate problèmes de biais subtils |
| Ignorer compromis coût-qualité | Optimiser qualité ruine le projet | Suivre ratio qualité/coût | 2% gain précision coûte 10x plus |
Partie IV : Guide d'implémentation
4.1 Quand utiliser quelle architecture
Commencez par votre besoin principal et suivez le chemin de décision :
| Si vous avez besoin de... | Meilleure architecture | Focus évaluation clé | Pièges courants |
|---|---|---|---|
| Connaissances fréquemment mises à jour | RAG | Qualité retrieval, attribution sources | Sur-ingénierie retrieval |
| Expertise spécifique domaine | Fine-tuning | Précision domaine, cohérence style | Oubli catastrophique |
| Automatisation de tâches | Agents | Précision usage outils, complétion tâche | Exécution outils peu fiable |
| Précision coût-efficace | RAG + Prompting | Usage contexte, qualité réponse | Fragilité des prompts |
| Contrôle maximum | Fine-tuning + RAG | Retrieval et génération | Explosion de complexité |
| Workflows complexes | Systèmes multi-agents | Coordination inter-agents | Difficulté de débogage |
Partie V : Guide de Dépannage
Quand les choses tournent mal - et elles le feront - voici votre guide pratique pour diagnostiquer et résoudre les problèmes courants.
5.1 Problèmes Courants et Solutions
Quand un problème est détecté, identifiez d'abord le type :
| 🔍 Symptôme | 🎯 Cause Probable | 🔬 Comment Investiguer | ✅ Solution |
|---|---|---|---|
| Hallucinations en hausse | Mauvaise qualité retrieval | Vérifier scores pertinence contexte | • Améliorer stratégie chunking • Améliorer modèle embedding • Ajouter validation retrieval |
| Réponses lentes | Contextes surdimensionnés | Tracer usage tokens par requête | • Optimiser fenêtre contexte • Implémenter compression • Utiliser réponses streaming |
| Mauvais usage outils | Descriptions outils floues | Revoir logs sélection outils | • Améliorer descriptions outils • Ajouter exemples few-shot • Implémenter validation outils |
| Sorties incohérentes | Température élevée ou problèmes prompt | Vérifier paramètres génération | • Baisser température • Améliorer clarté prompt • Ajouter validateurs sortie |
| Coûts en hausse | Usage tokens inefficace | Surveiller patterns consommation tokens | • Optimiser prompts • Mettre en cache réponses communes • Utiliser modèles plus petits si possible |
| Insatisfaction utilisateurs | Désalignement avec besoins utilisateurs | Analyser patterns feedback | • Mettre à jour critères évaluation • Affiner métriques succès • Implémenter RLHF |
5.2 La Boucle de Feedback en Action
Le Cycle d'Amélioration Continue
- 11. L'Évaluation définit la baseline : « Bon = 0.85 de fidélité »
- 22. Le Monitoring détecte une déviation : « Alerte ! Fidélité à 0.65 »
- 33. L'Observabilité trouve la cause racine : « Nouveau format doc casse le chunking »
- 44. Solution identifiée : « Mettre à jour la stratégie de chunking »
- 55. La Ré-Évaluation valide le correctif : « Nouvelle stratégie : 0.90 de fidélité »
- 66. Mise à Jour Système : Métriques monitoring enrichies, meilleures traces, baselines mises à jour
Cela crée une spirale ascendante d'amélioration, pas juste une boucle ! Chaque cycle :
Conclusion : Votre Chemin à Suivre
🎯 Points Clés à Retenir
1. Les Trois Piliers Sont Inséparables : Évaluation, Monitoring et Observabilité travaillent ensemble pour créer des systèmes IA fiables. Vous avez besoin des trois.
2. L'Architecture Compte : RAG, Agents et modèles Fine-tunés nécessitent chacun des approches d'évaluation spécifiques. Une taille unique ne convient pas à tous.
3. L'Évaluation Continue est Non-Négociable : Contrairement aux logiciels traditionnels, les systèmes IA nécessitent une évaluation constante en production, pas seulement avant le déploiement.
4. Commencez Simple, Évoluez Continuellement : Commencez au Niveau 1 de maturité et construisez progressivement vos capacités. Le parfait est l'ennemi du bien.
5. Les Métriques Sont Transversales : La même métrique sert différents objectifs à travers les piliers - adoptez ce chevauchement plutôt que de le combattre.
💡 Réflexions Finales
Construire des systèmes GenAI fiables ne consiste pas à choisir entre Évaluation, Monitoring ou Observabilité - il s'agit d'orchestrer les trois en une symphonie d'amélioration continue. Chaque pilier renforce les autres, créant un système qui non seulement fonctionne mais s'améliore avec le temps.
Chaque problème en production est une opportunité d'apprentissage.
Avec une évaluation, un monitoring et une observabilité appropriés, vous transformez les problèmes en progrès, les bugs en insights, et les échecs en fonctionnalités. Le voyage du firefighting réactif vers l'amélioration proactive commence par la compréhension de ces trois piliers.
Des questions ? Des retours ? Des désaccords ? N'hésitez pas à partager vos réflexions - ce domaine évolue grâce à l'apprentissage collectif.
Comments
No comments yet. Be the first to comment!